
Overview of NLP
Getting Started with Python for NLP
Setting up the Python Environment for NLP
Basic Python Libraries for NLP Tasks
Text Preprocessing
Tokenization: Breaking Text into Individual Words or Sentences
Input Code:
import nltk
nltk.download('all')
from nltk import word_tokenize, sent_tokenize
sent = "Tokenization is the first step in any NLP pipeline. \
It has an important effect on the rest of your pipeline."
print(word_tokenize(sent))
print(sent_tokenize(sent)) Output:
[‘Tokenization’, ‘is’, ‘the’, ‘first’, ‘step’, ‘in’, ‘any’, ‘NLP’, ‘pipeline’, ‘.’, ‘It’, ‘has’, ‘an’, ‘important’, ‘effect’, ‘on’, ‘the’, ‘rest’, ‘of’, ‘your’, ‘pipeline’, ‘.’]
[‘Tokenization is the first step in any NLP pipeline.’, ‘It has an important effect on the rest of your pipeline.’]
Stopword Removal: Filtering Out Common Words
Stopwords are common words like ‘and’, ‘the’, ‘is’ that add little value in NLP tasks. Removing these words helps in focusing on the meaningful content.
NLTK library consists of a list of words that are considered stopwords for the English language. Some of them are : [i, me, my, myself, we, our, ours, ourselves, you, you’re, you’ve, you’ll, you’d, your, yours, yourself, yourselves, he, most, other, some, such, no, nor, not, only, own, same, so, then, too, very, s, t, can, will, just, don, don’t, should, should’ve, now, d, ll, m, o, re, ve, y, ain, aren’t, could, couldn’t, didn’t, didn’t].If we want to add any new word to a set of words then it is easy using the set method.
Input Code:
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
print(stopwords.words('english')) Output:
[‘i’, ‘me’, ‘my’, ‘myself’, ‘we’, ‘our’, ‘ours’, ‘ourselves’, ‘you’, “you’re”, “you’ve”, “you’ll”, “you’d”, ‘your’, ‘yours’, ‘yourself’, ‘yourselves’, ‘he’, ‘him’, ‘his’, ‘himself’, ‘she’, “she’s”, ‘her’, ‘hers’, ‘herself’, ‘it’, “it’s”, ‘its’, ‘itself’, ‘they’, ‘them’, ‘their’, ‘theirs’, ‘themselves’, ‘what’, ‘which’, ‘who’, ‘whom’, ‘this’, ‘that’, “that’ll”, ‘these’, ‘those’, ‘am’, ‘is’, ‘are’, ‘was’, ‘were’, ‘be’, ‘been’, ‘being’, ‘have’, ‘has’, ‘had’, ‘having’, ‘do’, ‘does’, ‘did’, ‘doing’, ‘a’, ‘an’, ‘the’, ‘and’, ‘but’, ‘if’, ‘or’, ‘because’, ‘as’, ‘until’, ‘while’, ‘of’, ‘at’, ‘by’, ‘for’, ‘with’, ‘about’, ‘against’, ‘between’, ‘into’, ‘through’, ‘during’, ‘before’, ‘after’, ‘above’, ‘below’, ‘to’, ‘from’, ‘up’, ‘down’, ‘in’, ‘out’, ‘on’, ‘off’, ‘over’, ‘under’, ‘again’, ‘further’, ‘then’, ‘once’, ‘here’, ‘there’, ‘when’, ‘where’, ‘why’, ‘how’, ‘all’, ‘any’, ‘both’, ‘each’, ‘few’, ‘more’, ‘most’, ‘other’, ‘some’, ‘such’, ‘no’, ‘nor’, ‘not’, ‘only’, ‘own’, ‘same’, ‘so’, ‘than’, ‘too’, ‘very’, ‘s’, ‘t’, ‘can’, ‘will’, ‘just’, ‘don’, “don’t”, ‘should’, “should’ve”, ‘now’, ‘d’, ‘ll’, ‘m’, ‘o’, ‘re’, ‘ve’, ‘y’, ‘ain’, ‘aren’, “aren’t”, ‘couldn’, “couldn’t”, ‘didn’, “didn’t”, ‘doesn’, “doesn’t”, ‘hadn’, “hadn’t”, ‘hasn’, “hasn’t”, ‘haven’, “haven’t”, ‘isn’, “isn’t”, ‘ma’, ‘mightn’, “mightn’t”, ‘mustn’, “mustn’t”, ‘needn’, “needn’t”, ‘shan’, “shan’t”, ‘shouldn’, “shouldn’t”, ‘wasn’, “wasn’t”, ‘weren’, “weren’t”, ‘won’, “won’t”, ‘wouldn’, “wouldn’t”]
Input Code:
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Sample text
text = "This is an example sentence showcasing the removal of stop words."
# Tokenize the text
words = word_tokenize(text)
# Filter out stop words
filtered_words = [word for word in words if word.lower() not in stopwords.words('english')]
print("Original Text:", words)
print("Text after Removing Stopwords:", filtered_words)
Output:
Text after Removing Stopwords: [‘example’, ‘sentence’, ‘showcasing’, ‘removal’, ‘stop’, ‘words’, ‘.’]
Input Code:
custom_stopwords = set(['example', 'showcasing'])
filtered_words_custom = [word for word in words if word.lower() not in custom_stopwords]
print("Text after Removing Custom Stopwords:", filtered_words_custom)
Output:
Stemming and Lemmatization
Stemming:
Input Code:
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
sentence = "Natural language processing is a fascinating field for data scientists."
# Tokenize the sentence
words = word_tokenize(sentence)
# Initialize the Porter Stemmer
stemmer = PorterStemmer()
# Stem each word in the sentence
stemmed_words = [stemmer.stem(word) for word in words]
# Print the original and stemmed words
print("Original words:", words)
print("Stemmed words:", stemmed_words)
Output:
Stemmed words: [‘natur’, ‘languag’, ‘process’, ‘is’, ‘a’, ‘fascin’, ‘field’, ‘for’, ‘data’, ‘scientist’, ‘.’]
Lemmatization:
Lemmatization, on the other hand, aims to reduce words to their base or root form, known as the lemma. Unlike stemming, lemmatization ensures that the resulting word is a valid word in the language.
Input Code:
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
# Example sentence
sentence = "Natural language processing is a fascinating field for data scientists."
# Tokenize the sentence
words = word_tokenize(sentence)
# Initialize the WordNet Lemmatizer
lemmatizer = WordNetLemmatizer()
# Lemmatize each word in the sentence
lemmatized_words = [lemmatizer.lemmatize(word) for word in words]
# Print the original and lemmatized words
print("Original words:", words)
print("Lemmatized words:", lemmatized_words)
Output:
Original words: [‘Natural’, ‘language’, ‘processing’, ‘is’, ‘a’, ‘fascinating’, ‘field’, ‘for’, ‘data’, ‘scientists’, ‘.’]
Lemmatized words: [‘Natural’, ‘language’, ‘processing’, ‘is’, ‘a’, ‘fascinating’, ‘field’, ‘for’, ‘data’, ‘scientist’, ‘.’]
Part-of-Speech Tagging: Identifying Grammatical Parts of Speech
Dive into part-of-speech tagging, a fundamental component that involves categorizing words based on their grammatical roles. Uncover how this
process enhances language comprehension.(POS) tagging is a fundamental task in Natural Language Processing (NLP) that involves assigning a
part-of-speech label (such as noun, verb, adjective, etc.) to each word in a sentence.
Input Code:
import nltk
from nltk.tokenize import word_tokenize
nltk.download('averaged_perceptron_tagger')
# Example sentence
sentence = "Natural language processing is a fascinating field for data scientists."
# Tokenize the sentence
words = word_tokenize(sentence)
# Perform POS tagging
pos_tags = nltk.pos_tag(words)
# Print the original words and their POS tags
print("Original words:", words)
print("POS tags:", pos_tags)
Output:
Original words: [‘Natural’, ‘language’, ‘processing’, ‘is’, ‘a’, ‘fascinating’, ‘field’, ‘for’, ‘data’, ‘scientists’, ‘.’]
POS tags: [(‘Natural’, ‘JJ’), (‘language’, ‘NN’), (‘processing’, ‘NN’), (‘is’, ‘VBZ’), (‘a’, ‘DT’), (‘fascinating’, ‘JJ’), (‘field’, ‘NN’), (‘for’, ‘IN’), (‘data’, ‘NNS’), (‘scientists’, ‘NNS’), (‘.’, ‘.’)]
Building NLP Models
Sentiment Analysis
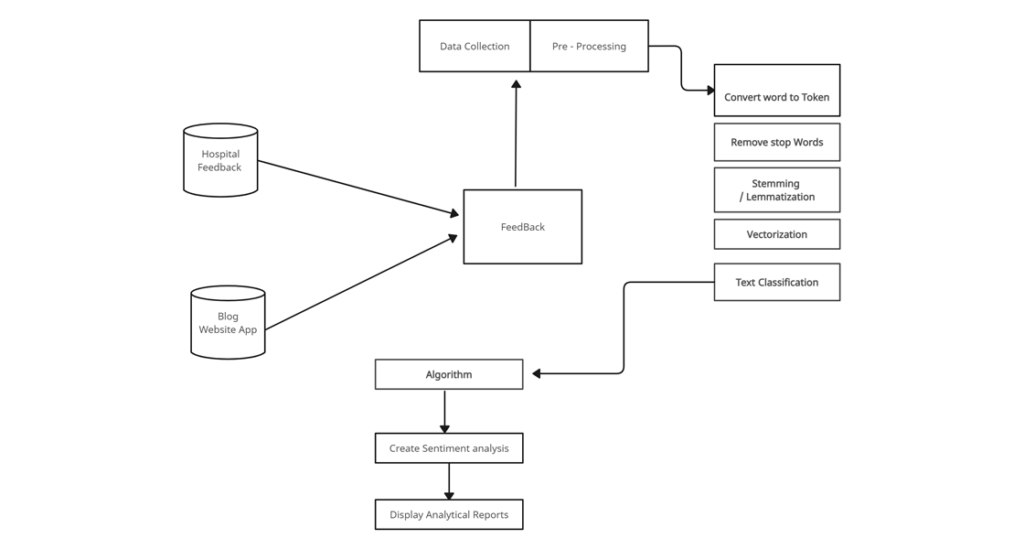
Sentiment analysis aims to understand the emotions and opinions expressed in textual data. It can be used on social media data, product reviews, and customer feedback.
Below is the example flow of real-time sentiment analysis:
Named Entity Recognition
Text Classification
Advanced NLP Techniques in Python
Advanced NLP techniques that allow for deeper analysis and understanding of text data.
Word Embeddings
Topic Modeling
Text Generation
Summary
Shivani Kaniya