
Enhancing AI Capabilities with RAG in Node.js: A Step-by-Step Tutorial
- Fast access to relevant information
- Cross-generational productivity
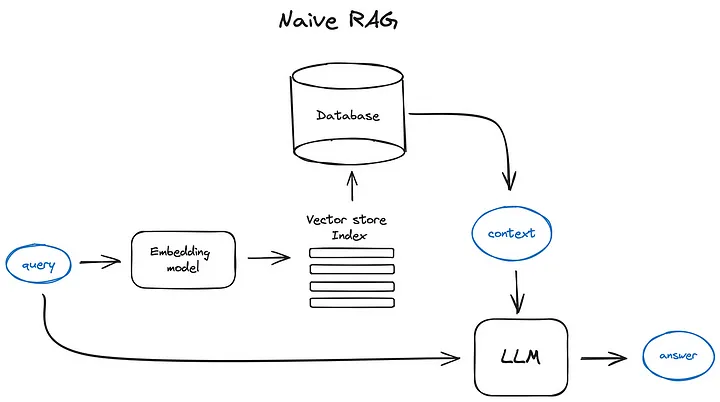
What is RAG (Retrieval Augmented Generation)?
RAG meaning - it is a hybrid approach that fuses two AI capabilities:
2. Generative models: These models generate text based on input prompts, providing coherent and context-aware responses.
How RAG Works:
2. Generate: The generative model uses the retrieved documents to create a more nuanced and contextually accurate response.
Setting Up RAG in Node.js:
Prerequisites:
- Node.js and npm
- MongoDB (you can use a local or hosted instance)
- LangChain, RAG llm-tools/embedjs and other required npm packages

6 Step-Guide For Implementing RAG In Node.js:
Pro Tip: Before diving in, ensure your development environment is set up with Node.js and the necessary packages.
Step 1: Initialize Your Project:
mkdir rag-nodejs-app cd rag-nodejs-app npm init -y
Step 2: Install Required Packages:
npm i @llm-tools/embedjs npm install @llm-tools/embedjs-mongodb
Step 3: Create A New .ENV file And Add The Required Environment Variables:
OPENAI_API_KEY = <YOUR_OPEN_AI_API_KEY>
Step 4: Create New Folders In Current Directory to Store Cache and Data Files :
Step 5: Create A New File As An Index.js file & add below content:
import "dotenv/config";
import * as path from "node:path";
import { RAGApplicationBuilder, TextLoader } from "@llm-tools/embedjs";
import { LmdbCache } from "@llm-tools/embedjs/cache/lmdb";
import { MongoDb } from "@llm-tools/embedjs/vectorDb/mongodb";
import * as fs from "fs";
import express from "express";
import cors from "cors";
const app = express();
app.use(express.json());
app.use(cors());
const port = 4000;
app.get("/initLoader", async (req, res) => {
//From sample file add loaders.
const llmApplication = await new RAGApplicationBuilder()
.setCache(new LmdbCache({ path: path.resolve("./cache") }))
.setVectorDb(
new MongoDb({
connectionString:
"MONGODB_CONNECTION_URI",
})
)
.build();
const folderPath = "./files";
// Read all files in the folder
fs.readdir(folderPath, (err, files) => {
if (err) {
return console.error(`Unable to scan directory: ${err}`);
}
// Loop through the files
for (const file of files) {
const filePath = path.join(folderPath, file);
// Perform an operation on each file, for example, log file name
console.log(`Processing file: ${filePath}`);
// You can read the file contents if needed
fs.readFile(filePath, "utf8", async (err, data) => {
if (err) {
console.error(`Error reading file: ${err}`);
} else {
console.log(`File content of ${file}`);
const fileType = getFileExtension(file);
switch (fileType) {
case "txt":
await llmApplication.addLoader(new TextLoader({ text: data }));
break;
case "pdf":
await llmApplication.addLoader(
new PdfLoader({
filePathOrUrl: path.resolve(filePath),
})
);
default:
break;
}
}
});
}
});
res.send(200);
});
const getFileExtension = (fileName) => {
return fileName.split(".").pop(); // Returns the last part after the last '.'
};
app.post("/searchQuery", async (req, res) => {
const { searchText } = req.body;
console.log("inside add loader Post call", req.body);
const llmApplication = await new RAGApplicationBuilder()
.setCache(new LmdbCache({ path: path.resolve("./cache") }))
.setVectorDb(
new MongoDb({
connectionString:
"MONGODB_CONNECTION_URI",
})
)
.build();
let result = await llmApplication.query(searchText);
console.log(searchText, " ==> ", result.content);
res.status(200).json({ result: result.content });
});
app.listen(port, () => {
console.log(`Example app listening on port ${port}`);
});
Explanation Of The Above Code:
1. Importing Dependencies
- dotenv: Loads environment variables from a .env file.
- path: Manages file and directory paths.
- @llm-tools/embedjs: Provides tools to create a RAG application using RAGApplicationBuilder, TextLoader, and MongoDB for vector database integration.
- fs: Handles file system operations, like reading directory contents.
- express and cors: Used to set up a web server that can handle JSON payloads and enable CORS for cross-origin requests.
2. Application Setup
- Express App Initialization: Creates an express app instance, allowing JSON body parsing and CORS.
- Port Setup: Sets the server to run on port 4000.
3. API Endpoints
- /initLoader (GET):
- Initializes the RAG application with an LMDB cache for caching embeddings and connects to a MongoDB vector database.
- Reads files from the ./files directory, processes each file based on its extension, and adds it to the RAG application as a loader:
- .txt files are processed using TextLoader.
- .pdf files are processed using a PdfLoader (though PdfLoader isn’t imported here, assuming it’s defined or available in the project).
- /searchQuery (POST):
- Takes a search query (searchText) from the request body, creates a new RAG application instance, and uses the MongoDB vector store and LMDB cache.
- Runs a query on the RAG application with the searchText and retrieves results, which are then returned as JSON.
4. Utility Function
- getFileExtension: Returns the file extension by splitting the file name string on the last . character.
5. Server Initialization
- app.listen: Starts the Express server and logs the port it's running on.
6: Build the UI and Connect the API
Conclusion
FAQS
Retrieval Augmented Generation (RAG) is a technique that combines information retrieval with Gen AI models. It retrieves relevant data from a database or external source and uses this information to generate more accurate, contextually aware responses. RAG in AI enhances the capabilities of AI models by ensuring the responses are not just generated but are informed by specific, up-to-date data, making it ideal for complex applications like customer support or knowledge management.
RAG enhances AI’s ability to generate more precise, contextually relevant answers by leveraging external data sources. It improves the accuracy of responses by incorporating up-to-date information, reducing irrelevant information. Additionally, RAG minimizes the need to train large language models with vast amounts of data, making it a cost-effective approach. It enables AI systems to be more adaptable and dynamic, especially in real-time applications like content generation and customer support.
RAG works by combining two processes: Retrieval and Generation. First, the system retrieves relevant information from a large database or knowledge source using techniques like search engines or vector databases. Then, a generative AI model, such as a transformer, uses this retrieved data to generate coherent, human-like responses. This process ensures that responses are not only generated from the model’s training but also informed by the most relevant data available.
The key difference between Retrieval Augmented Generation (RAG) and Semantic Search lies in the output. Semantic search focuses on retrieving the most relevant documents or data based on the meaning of the query, whereas RAG not only retrieves the information but also generates a human-like response using that data. RAG combines retrieval with generation, allowing for context-specific, conversational AI, while semantic search is more about finding information rather than generating new content from it.
There are several approaches to implementing RAG, primarily based on the retrieval mechanism and generation model.
- One approach is to use traditional search engines or vector-based retrieval for data access, combined with deep learning-based models for generation.
- Another approach involves using specialized vector databases, which optimize the retrieval of information.
- Hybrid methods integrate RAG with other AI techniques, such as reinforcement learning, to further improve accuracy and response generation across diverse use cases.



